

Kimi K2 Thinking is the smartest open-source model ever released. A 1 trillion parameter reasoning model that matches GPT-5 and Claude Sonnet 4.5 on the hardest benchmarks. But raw intelligence means nothing if you can't deploy Kimi K2 Thinking efficiently.
At Simplismart, we've built a production-ready inference stack for Kimi K2 Thinking that delivers:
- 117ms time to first token (TTFT), under production load tuned for real-world latency constraints.
- 173+ tokens per second throughput
- Optimized NVFP4 quantization for NVIDIA Blackwell GPUs
- Hybrid Parallelism for optimal latency
This post details the technical work behind making trillion-parameter inference not just possible, but fast as well.
Why Kimi K2 Thinking Matters
Before diving into how to deploy Kimi K2 Thinking optimally, let's understand what makes this model so special.
The First Open-Source Model to Match Frontier AI
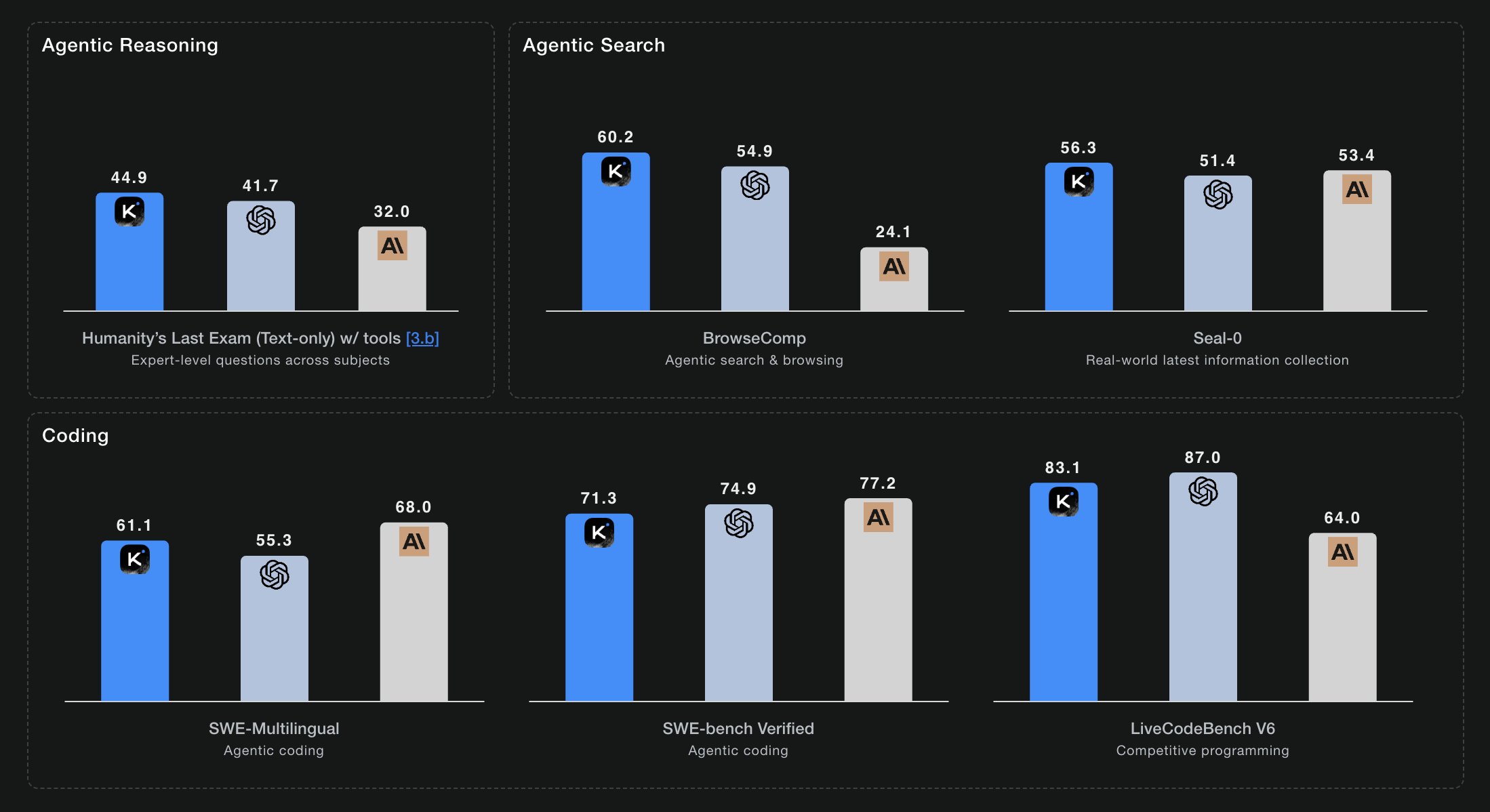
Kimi K2 Thinking is the model that closed the intelligence gap between open and closed-source AI. It doesn't just compete with closed-source models, it beats them:
Built for Agentic Workflows
What truly sets K2 Thinking apart is its stability over long-horizon tasks. Most models degrade after 30-50 tool calls and they lose context, start hallucinating, or drift from the original goal.
K2 Thinking maintains coherent, goal-directed behavior across 200-300 consecutive tool invocations. This makes it ideal for:
- Autonomous coding agents that write, test, and debug iteratively
- Research workflows spanning hundreds of web searches and document analyses
- Complex business logic requiring multiple API calls and validations
Challenge: Agentic workloads with hundreds of tool calls mean hundreds of inference requests with overlapping context. Without the right infrastructure, you're paying for redundant prefill computation on every single call.
The Model at a Glance
The key insight: despite having 1T parameters, only 32B are active per inference. This sparse activation is what makes trillion-parameter models deployable, but it also introduces unique optimization challenges.
How to Deploy Kimi K2 Thinking: Simplismart's Inference Optimizations
1. NVFP4 Quantization for Blackwell GPUs
Kimi K2 Thinking ships with native INT4 quantization, which is trained using Quantization-Aware Training (QAT) during post-training. This is great for Hopper GPUs (H100/H200) but to unlock maximum performance on NVIDIA Blackwell (B200), we need NVFP4.
Why NVFP4
NVFP4 is NVIDIA's new microscaling format optimized for Blackwell Tensor Cores. Unlike INT4, it uses a floating-point representation with dual scale factors, providing better precision characteristics for the Blackwell architecture.
INT4: [sign bit] + [3 value bits] + single scale factor
NVFP4: [sign bit] + 2 [exponent] + [mantissa] + dual scale factors
Our Conversion Pipeline
There's no direct INT4 → NVFP4 conversion path. We built a multi-stage pipeline using LLM Compressor:
- Dequantize INT4 → BF16: Using the compressed-tensors library to apply scale factors and convert weights
- Quantize BF16 → NVFP4: Using TensorRT Model Optimizer for Blackwell-native quantization
This process is compute-intensive but only needs to run once. The result: full Blackwell Tensor Core utilization with the precision characteristics optimized for this architecture.
Important: The model was trained at INT4 precision, hence no information is lost during the conversion. NVFP4 just enables us to run on Blackwell hardware with native performance.
Hybrid Parallelism: TP + EP for Optimal Latency
At 1 trillion parameters, even with INT4 quantization, to deploy Kimi K2 Thinking it requires careful parallelism strategy. We run on 8×B200 nodes with a hybrid approach combining Tensor Parallelism (TP) and Expert Parallelism (EP).
The Parallelism Landscape
Our Hybrid Approach
For MoE models like K2 Thinking, pure TP would require all-to-all communication for expert routing. Pure EP would underutilize GPUs when experts aren't perfectly balanced.
Our configuration:
- TP8 for attention layers: Maximizes throughput on the dense attention computation
- EP for expert layers: Distributes the 384 experts efficiently across GPUs
- NVLink optimization: All communication happens over high-bandwidth NVLink/NVSwitch within a single node
The result: optimal balance between latency and throughput without the bandwidth penalties of multi-node inference.
Performance Benchmarks: Simplismart vs Baseline vLLM
We benchmarked Kimi K2 Thinking on 8×B200 GPUs, comparing Simplismart's optimized stack against baseline vLLM (TP8 configuration):
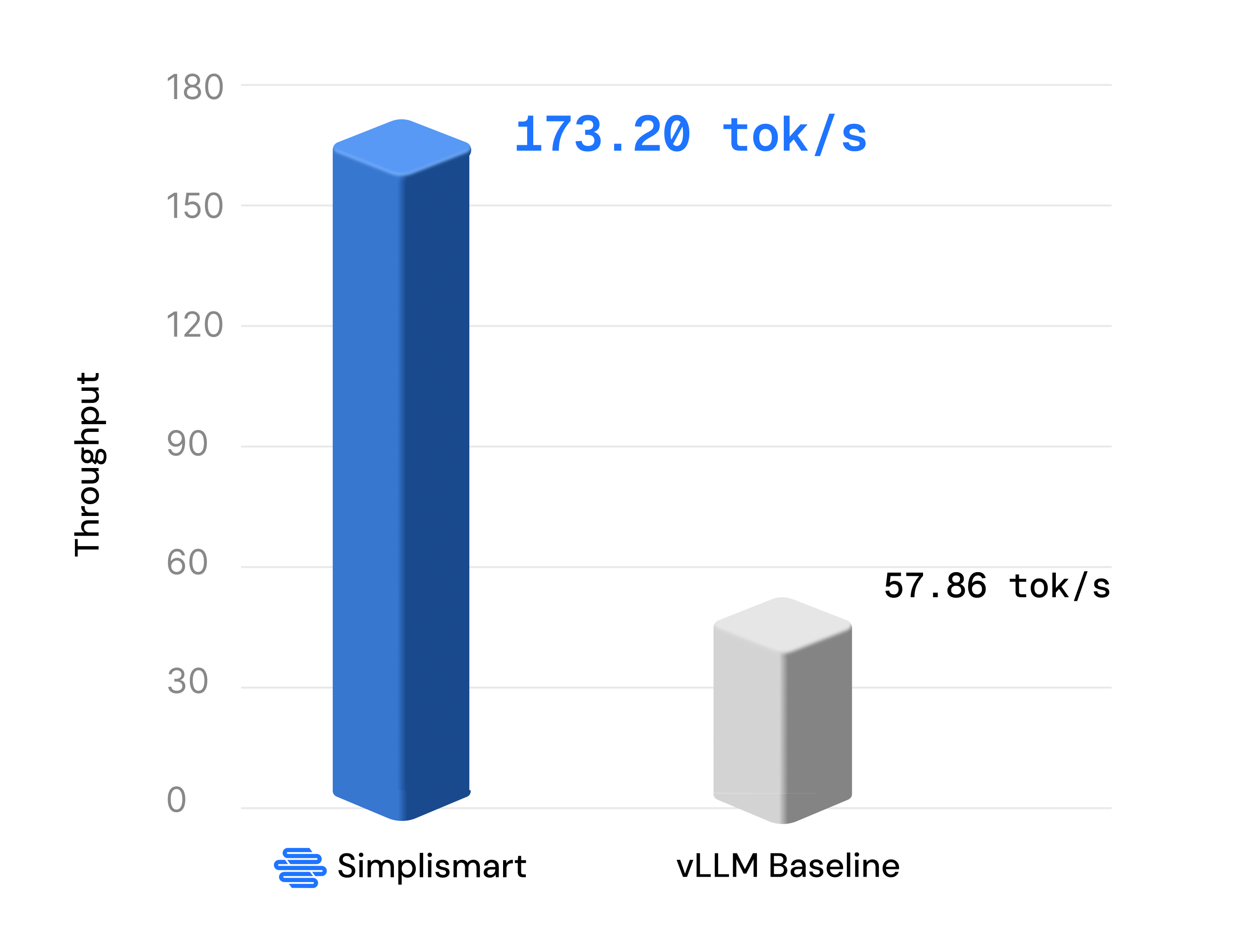
This 3x throughput improvement comes from our combined optimizations: NVFP4 quantization unlocking full Blackwell Tensor Core utilization, hybrid TP+EP parallelism minimizing communication overhead, and architecture-specific tuning for the MoE model structure.
The performance gains translate directly to production impact. For agentic workflows requiring hundreds of sequential calls, the 117ms TTFT ensures responsive interactions while maintaining the model's trillion-parameter intelligence.
When to Deploy Kimi K2 Thinking
Kimi K2 Thinking excels at:
✅ Autonomous agents requiring 100+ sequential tool calls
✅ Complex reasoning tasks (math, code, research)
✅ Long-context analysis up to 256K tokens
✅ Multi-step coding with iterative debugging
Consider alternatives when:
❌ Simple Q&A that doesn't need deep reasoning
❌ Latency-critical applications requiring <50ms TTFT
❌ Cost-sensitive workloads with simple queries
Conclusion
Kimi K2 Thinking represents a new era of open-source AI, a trillion-parameter intelligence that rivals the best closed models. But deploying it efficiently requires purpose-built infrastructure.
At Simplismart, we've invested heavily in the optimizations that matter:
- NVFP4 quantization for Blackwell hardware
- Hybrid TP+EP for optimal latency and throughput
The result: 117ms TTFT and 173 tokens/second GPT-5-level intelligence and open-source flexibility.
Ready to build with the smartest open-source model? Get started with Simplismart today.



