
The dilemma of high latency and slow inference
LLMs, which have billions of parameters, are known to require a significant amount of computation for inference. This results in delayed response times for real-time applications like chatbots and virtual assistants, which is a major issue.
Optimizing LLMs for decreasing latency
In this blog, we confront the challenge of slow LLM inference through a multifaceted strategy. Let's start with the basic techniques to speed up LLM inference. These techniques have helped Simplismart increase the throughput of a Llama 2-7B from 120 output tokens to 4000+ output tokens per second on a single A100 machine with techniques such as batching.
Speeding up inference with batching
Batching multiple requests that use the same model and spreading out the memory cost of weights can improve GPU utilization and throughput. Larger batches processed together on the GPU leverage the chipsets better. However, increasing batch sizes can only go so far because there's a risk of having a memory overflow.
Increasing speeds with speculative inference
Speculative inference, also known as speculative sampling, revolutionizes autoregressive model execution. Traditional models generate text token by token, hindering parallelization. Speculative inference bypasses this by creating a draft extension using a faster LLM and verifying it in parallel. If the verification aligns with the draft, tokens are accepted. LLM inference is sped up using a smaller draft generator and a larger verifier. These methods optimize computational efficiency and accuracy in parallel execution, redefining the capabilities of autoregressive models.
Using quantization to turn a high-precision model into a low-precision model
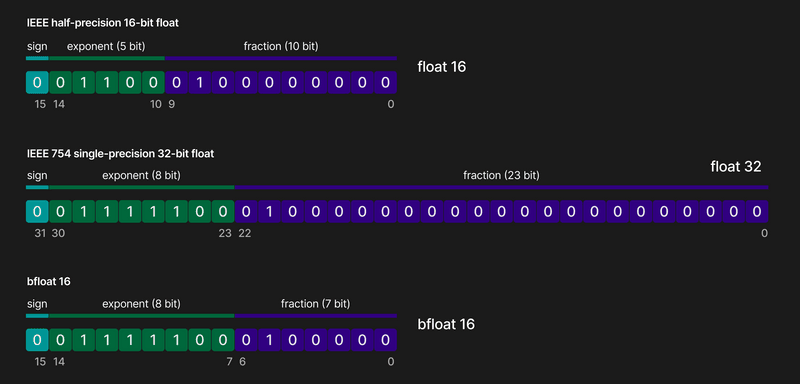
This method involves reducing the precision of the model's weights from high-precision formats to lower-precision formats. Let's take an example of going from a 32-bit float to a 16-bit float quantized model. This reduction virtually halves the model's memory footprint, increasing inference speeds and saving costs without any significant loss in quality. You can read about quantising models with Huggingface here.
Speeding up LLMs with pruning and sparsity
Pruning entails identifying and eliminating insignificant connections within the LLM's architecture. By removing these connections, you can create a more streamlined model that requires fewer computations during inference, thus enhancing speed.
Another interesting concept in speeding up LLMs is that of Sparsity. Sparse matrices represent data efficiently by storing only non-zero values and their locations, saving memory. Combining sparse matrices with techniques like quantization speeds up computations. GPUs have special features to handle structured sparsity, making them even faster. Future research aims to optimize large language models using these techniques for faster processing.
Knowledge Distillation
This technique entails training a more compact and less complex "student" model to imitate the performance of a larger and more intricate "teacher" model. The student network learns to replicate the performance of the teacher network by optimizing a loss function that measures the difference between their outputs. Leveraging the knowledge encapsulated in the teacher model, the student model achieves comparable accuracy with expedited inference speeds.
Scaling up LLMs with model parallelization
When we talk about reducing a model's memory usage, one trick is to split it across multiple GPUs. This helps spread the workload, allowing us to use bigger models or process more data simultaneously. Model parallelization becomes important when dealing with models that need more memory than one device can handle. There are several ways of parallelizing LLMs based on how the model weights are split, the most common being pipeline parallelism and tensor parallelism.
- Pipeline parallelism divides a model into chunks, running each on sequential devices, reducing memory needs.
- Tensor parallelism breaks layers into smaller blocks, which can run on different devices. It's great for tasks like attention in transformers. However, it can't split all operations and may need extra memory for certain tasks like LayerNorm and Dropout.
Speeding up attention mechanisms with flash-attention
Flash Attention is a revolutionary algorithm that changes how large language models (LLMs) pay attention to words. It simplifies things by splitting up the usual process into smaller steps. This means it doesn't need as much memory for big pieces of text but still gives accurate results. Even though it uses more computing power, it's quicker than the old way because it manages memory better on-chip. Overall, Flash Attention is a big step forward for LLMs, making them faster and more efficient without sacrificing accuracy.
How Simplismart helps optimise LLMs?
Simplideploy, our deployment suite, is a one-stop solution for speeding up LLMs. It uses many more application layer, model layer, and kernel layer techniques than mentioned in this blog. We discuss clients' accuracy, speed, and cost requirements and then help optimise LLMs on specific compute units.
Check out how you can streamline your MLOps processes using Simplismart here.
Democratizing LLM Inference Access
Simplismart makes LLMs more accessible to a wider range of consumers and developers by reducing the computational resources needed to run them. This further promotes innovation and adoption in this new field.
Conclusion
Simplismart offers a strong solution for accelerating open-source LLM inference. By combining quantization, pruning, and knowledge distillation, Simplismart improves LLM efficiency without sacrificing accuracy. This breakthrough opens up new possibilities for using LLMs in many real-world applications, propelling innovation in the NLP space.



