


We're excited to announce Day-0 support for NVIDIA Nemotron 3 Ultra on Simplismart.
As one of NVIDIA's launch partners for the Nemotron 3.x family, Simplismart customers can immediately deploy and optimize Nemotron 3 Ultra for production-scale agentic AI workloads.
Built for advanced reasoning and long-context execution, Nemotron 3 Ultra enables organizations to power a new generation of AI agents capable of handling complex, multi-step tasks. Simplismart's inference platform helps teams maximize model performance through fine-grained control over scheduling, batching, memory management, and workload prioritization.
In our benchmarking on NVIDIA 8xB200 GPUs, we achieved up to 50% higher throughput than TensorRT-LLM with MTP and NVFP4 enabled, reaching 508 tok/s at concurrency 1,800 tok/s at concurrency 10, and 6,900 tok/s at concurrency 100 on 10K-token input workloads. These optimizations allow teams to efficiently serve both latency-sensitive interactive agents and high-concurrency background workloads on the same infrastructure.
Together, NVIDIA Nemotron 3 Ultra and Simplismart provide a production-ready foundation for deploying enterprise-grade AI agents at scale.
The New Bottleneck in Agentic AI Is No Longer Model Quality
Agentic systems place very different demands on inference infrastructure than traditional chat applications.
As agents interact with tools, gather information, and execute multi-step workflows, their context grows rapidly. Requests become larger, reasoning chains become longer, and latency becomes harder to control. At the same time, infrastructure must efficiently serve both interactive agents that need fast responses and background agents that prioritize throughput.
These requirements make inference optimization a critical part of deploying agentic AI at scale and are exactly the problems NVIDIA Nemotron 3 Ultra is designed to solve.
Introducing NVIDIA Nemotron 3 Ultra
Nemotron 3 Ultra is NVIDIA's open frontier reasoning and orchestration model built for long-running agentic workflows.
The model is designed to serve as the reasoning and planning layer within multi-agent systems, making it particularly suited for:
- Agent orchestration
- Complex enterprise workflows
- Coding agents
- Deep research systems
- Long-horizon planning
- Multi-step reasoning tasks
Key Architecture Highlights
- 550B parameter Mixture-of-Experts architecture
- 55B active parameters per forward pass
- Hybrid Transformer-Mamba architecture
- Combines transformer attention capabilities with the efficiency benefits of state-space models
- Up to 1 million token context length
- Text input and text output
- Support for BF16 and NVFP4 precision
- Built specifically for high-throughput reasoning and long-running agent workflows
The result is a model optimized for the operational realities of production agent systems.
Why Inference for Agentic Workloads Is Fundamentally Different
At first glance, Nemotron's Mixture-of-Experts architecture appears highly efficient because only a subset of parameters are activated during inference.
In practice, large-scale agent deployments introduce several additional bottlenecks.
1. KV Cache Growth Becomes the Dominant Memory Constraint
Nemotron 3 Ultra supports context windows of up to 1 million tokens. For long-running agents, context grows continuously as tool calls, retrieved documents, observations, and reasoning traces accumulate over time.
Without intelligent cache management, memory consumption increases rapidly, reducing concurrency and increasing latency.
2. Reasoning Tokens Increase End-to-End Latency
Reasoning models generate extensive chains of thinking before producing final outputs. Even when the final response is short, the model may generate thousands of intermediate reasoning tokens.
For interactive applications, this can significantly impact user-perceived responsiveness.
3. Agent Traffic Has Highly Variable Characteristics
Traditional chat workloads tend to exhibit relatively predictable request sizes. Agentic workloads do not.
An agent's first request may contain only a few hundred tokens. Several tool calls later, the same session may contain hundreds of thousands of tokens.
Static batching strategies struggle to maintain efficiency across such variability.
4. Not Every Agent Requires the Same SLA
Consider two simultaneous requests:
- A coding copilot assisting a developer in real time.
- A research agent synthesising information overnight.
The first requires low latency. The second prioritises throughput and cost efficiency.
Treating both requests identically leads to poor infrastructure utilisation and suboptimal user experience.
Optimising Nemotron 3 Ultra on Simplismart
Nemotron 3 Ultra incorporates NVIDIA innovations such as NVFP4 quantisation and Multi-Token Prediction (MTP), enabling higher throughput and lower memory bandwidth requirements.
Simplismart extends these capabilities with infrastructure-level optimisations specifically designed for agentic inference. These enhancements build on NVIDIA's MTP and NVFP4 innovations to deliver up to 50% higher throughput at low concurrency, 10% higher throughput at moderate concurrency, and 19% higher throughput at large-scale serving workloads (at 10,000 input tokens).
KV Cache Offloading and Prefix Sharing
Long-context agent workloads place substantial pressure on GPU memory.
Simplismart addresses this through two complementary mechanisms:
KV Cache Offloading
Extends effective cache capacity by utilising CPU memory.
Prefix Caching
- Shares common prompt prefixes across requests.
- Eliminates redundant computation.
- Reduces memory footprint for deployments with shared system prompts, tool definitions, and agent instructions.
The result is higher concurrency and improved utilisation without sacrificing context length.
Relaxed Thinking for Faster Reasoning
Simplismart leverages speculative decoding using Nemotron's Multi-Token Prediction heads.
For reasoning workloads, we apply a lower acceptance threshold to intermediate thinking tokens.
The key observation is that reasoning traces do not require exact token-level matching with the full model at every step to arrive at the same high-quality final answer. This enables significantly faster reasoning generation while maintaining output quality.
The impact is particularly visible in interactive agent deployments. At concurrency 1 and 10,000 input tokens, Simplismart achieves 508 tok/s compared to 339 tok/s with TensorRT MTP+NVFP4, representing a 50% throughput improvement. This directly translates into faster reasoning generation and lower user-perceived latency for coding assistants, copilots, and other interactive agents.
Deployment Profiles Tuned for Different Agent Types
Agent workloads rarely share identical performance requirements.
Simplismart allows teams to deploy multiple inference profiles optimized for distinct workload characteristics.
For Interactive Agents
- Increased speculative token generation
- Lower latency
- Faster user interactions
For Background Agents
- Higher throughput
- Better GPU utilization
- Improved cost efficiency
Organizations can route workloads to dedicated deployment profiles while serving all traffic from a unified platform.
For mixed workloads operating at moderate concurrency, Simplismart reaches 800 tok/s compared to 730 tok/s on TensorRT MTP+NVFP4, delivering a 10% throughput improvement. This enables higher agent density per GPU while maintaining service quality across different workload classes.
Fine-Grained Continuous Batching
As agent sessions evolve, request sizes change accordingly.
Simplismart's scheduler continuously adapts batch composition based on current memory availability and request characteristics.
This enables consistently high GPU utilization across workloads ranging from short prompts to extremely long-context sessions.
The benefits become especially apparent at scale. At concurrency 100, Simplismart delivers 6900 tok/s, compared to 5800 tok/s on TensorRT MTP+NVFP4, maintaining an 19% throughput advantage even under heavy serving loads.
Priority-Aware Scheduling
One of the most important requirements in production agent systems is workload prioritization.
Simplismart's inference scheduler supports priority-based request handling, allowing organizations to:
- Prioritize user-facing agents
- Protect latency-sensitive workloads
- Prevent background tasks from monopolizing resources
- Improve overall cluster efficiency
This makes it possible to serve mixed agent workloads from shared infrastructure without compromising responsiveness.
Benchmark Results
To quantify the impact of these optimizations, we benchmarked NVIDIA Nemotron 3 Ultra on 1 NVIDIA B200 node across different input sequences and concurrency levels.
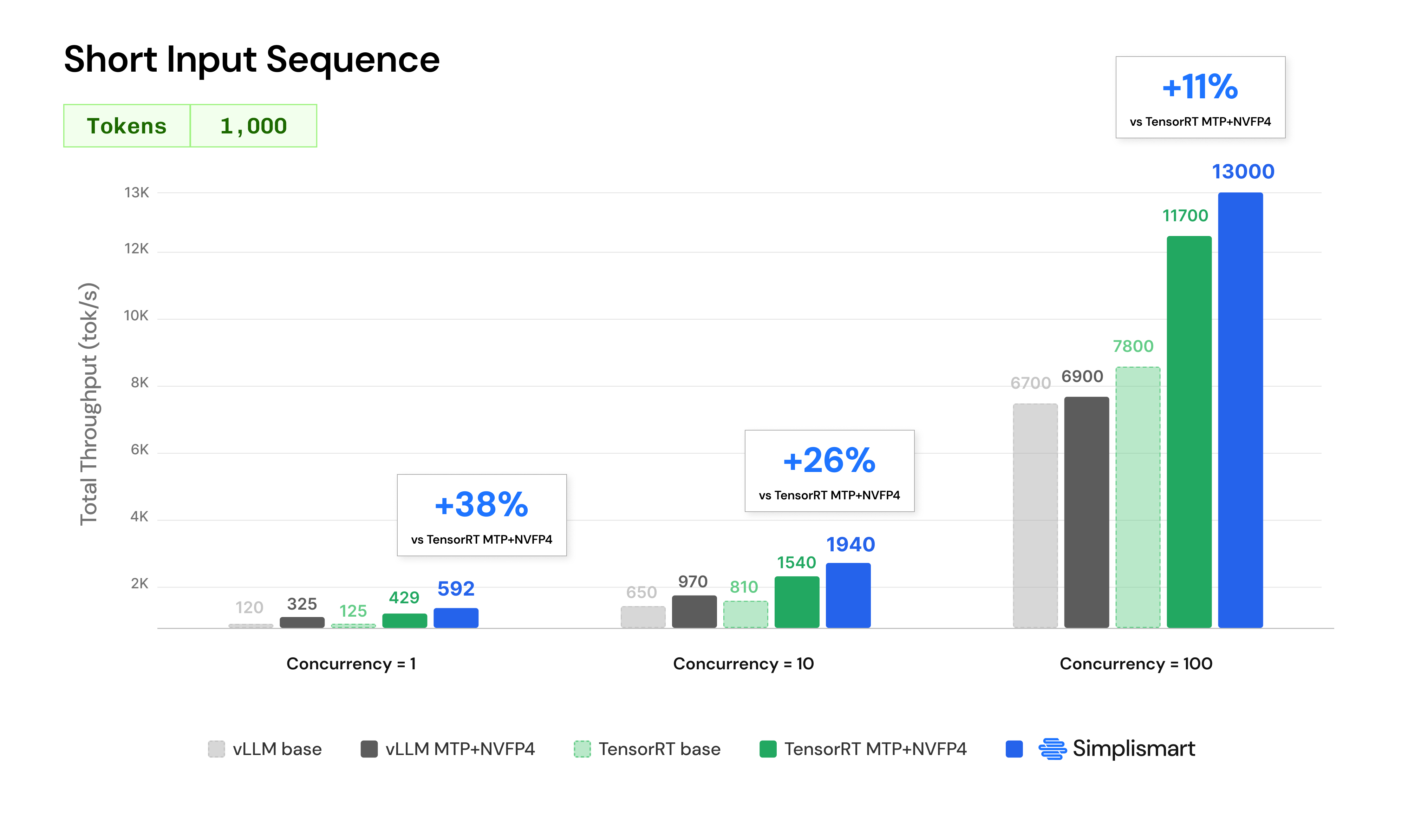
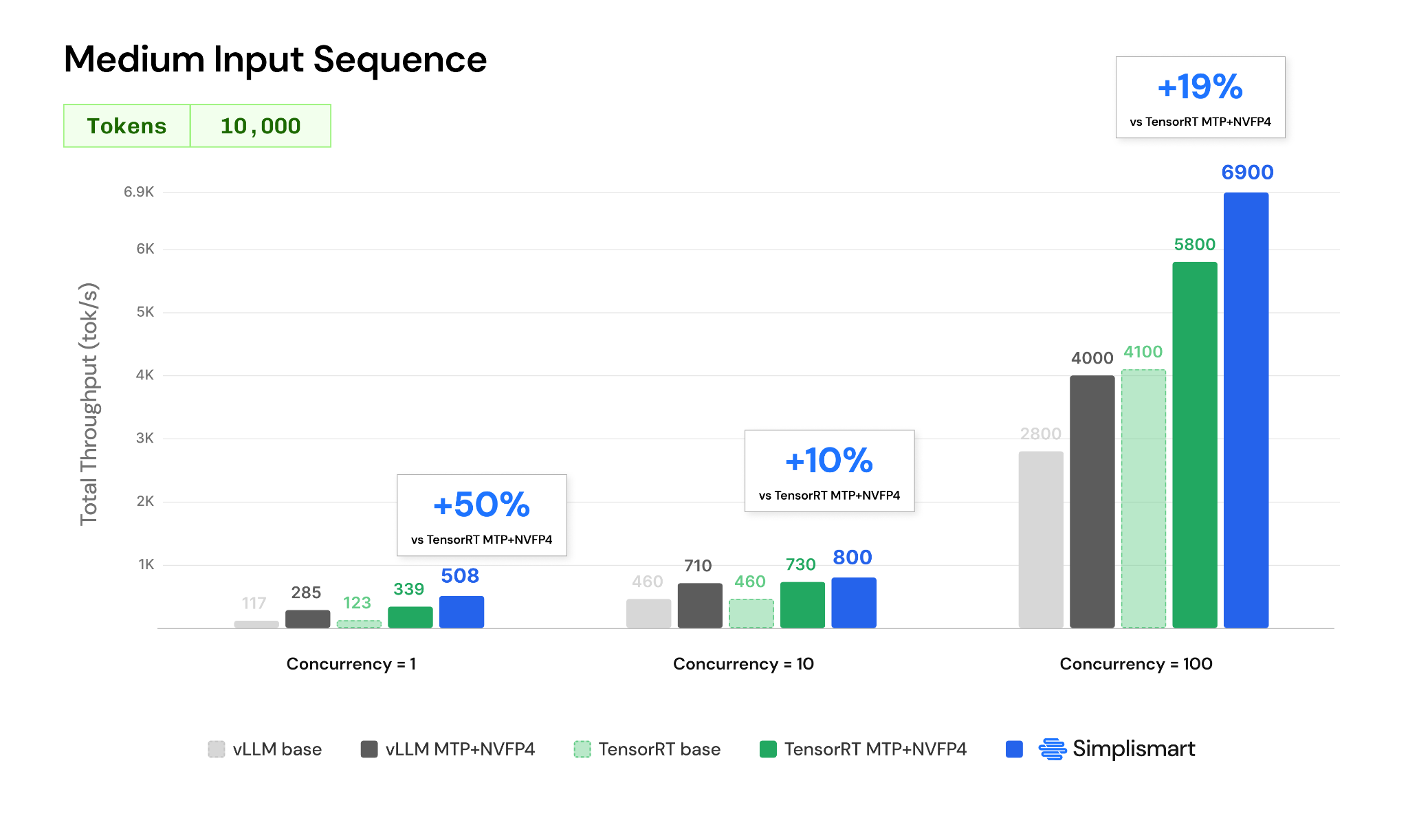
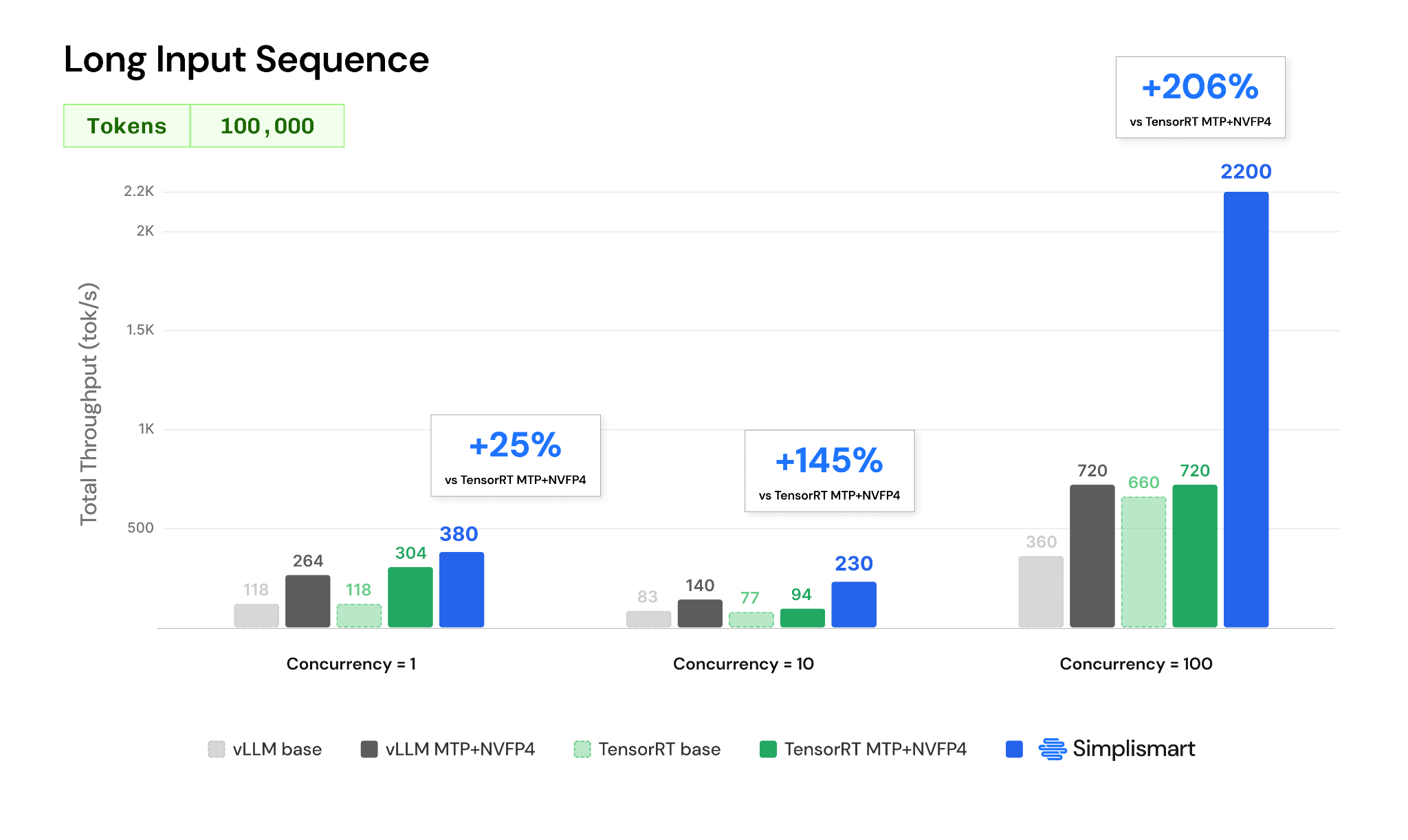
These improvements demonstrate that infrastructure-level optimizations remain critical even after enabling advanced model-level techniques such as NVFP4 quantization and Multi-Token Prediction.
Deploy Nemotron 3 Ultra Today
The next generation of AI applications will be built around agents rather than chat interfaces.
Successfully deploying these systems requires more than a powerful model. It requires an inference stack capable of handling long contexts, complex reasoning, heterogeneous traffic patterns, and mixed latency requirements.
With consistent better performance than TensorRT + MTP + NVFP4, Simplismart provides one of the most efficient production environments for deploying NVIDIA Nemotron 3 Ultra at scale.
As a Day-0 NVIDIA launch partner, Simplismart enables teams to deploy NVIDIA Nemotron 3 Ultra immediately with production-grade inference optimizations purpose-built for agentic AI.
Whether you're building coding agents, research assistants, enterprise copilots, or autonomous workflows, Simplismart provides the infrastructure needed to run them efficiently at scale.
Deploy Nemotron 3 Ultra on Simplismart today! - BOOK A DEMO



