

Modern diffusion transformers for video (DiTs) such as Wan-class models operate over extremely long token sequences. Even a short 720p clip with ~81 frames can produce hundreds of thousands of latent tokens once spatial×temporal patches are arranged into a transformer sequence.
A single GPU cannot hold all attention keys/values for such sequence lengths. Multi-GPU parallelism is therefore required to fit memory and keep latency under control.
This post shows how Simplismart implements a Hybrid Parallelism technique that combines Ulysses (sequence) parallelism and Ring attention to push Video DiT inference beyond single-device limits, while reducing communication overhead and improving load balance.
Problem setup: Tensor size and bottlenecks
Transformer attention in DiTs typically consumes tensors of shape:
[B, H, N, D]
- B: batch size
- H: attention heads
- N: sequence length (spatial × temporal tokens)
- D: head dimension
With ~81 video frames at 720p, N can approach ~80K. At this scale, attention kernels become the bottleneck:
- K/V caches exceed a single device’s memory.
- Thread blocks stall waiting for scheduling on SMs.
- DRAM bandwidth pressure increases.
- Cross-GPU communication quickly dominates when naively sharded.
Ulysses (Sequence) Parallelism component in Hybrid Parallelism
In this technique, the first component is Ulysses, also known as sequence parallelism.
This method partitions the sequence dimension (N) across multiple GPUs, enabling attention computation over extremely long sequences that would otherwise exceed the memory limits of a single device.
Core Principle
Each GPU maintains a full copy of:
- All attention heads (H)
- All model parameters
However, it holds only a slice of the sequence tokens along N.
For a distributed system with P GPUs, the per-device tensor layout can be represented as:
[B, H, N/P, D]
(B,H,N,D are the same as defined above)
Attention Computation Flow
- Each GPU computes attention over its local subset of tokens using its local key/value (K/V) tensors.
- Partial attention scores are exchanged between GPUs to ensure global context coverage.
- After synchronization, each GPU aggregates the contributions to produce the final output corresponding to its assigned token block.
Advantages
- Substantial memory efficiency: The dominant dimension (N) is distributed, allowing for significantly larger context windows.
- Model consistency: Since all GPUs store the complete set of parameters, no model reconfiguration is required.
Limitations
- When the head count (H) is small, overall parallel utilization decreases, limiting speedup.
- Communication overhead remains non-trivial for extremely long sequences due to the need for cross-GPU synchronization during the attention exchange phase.
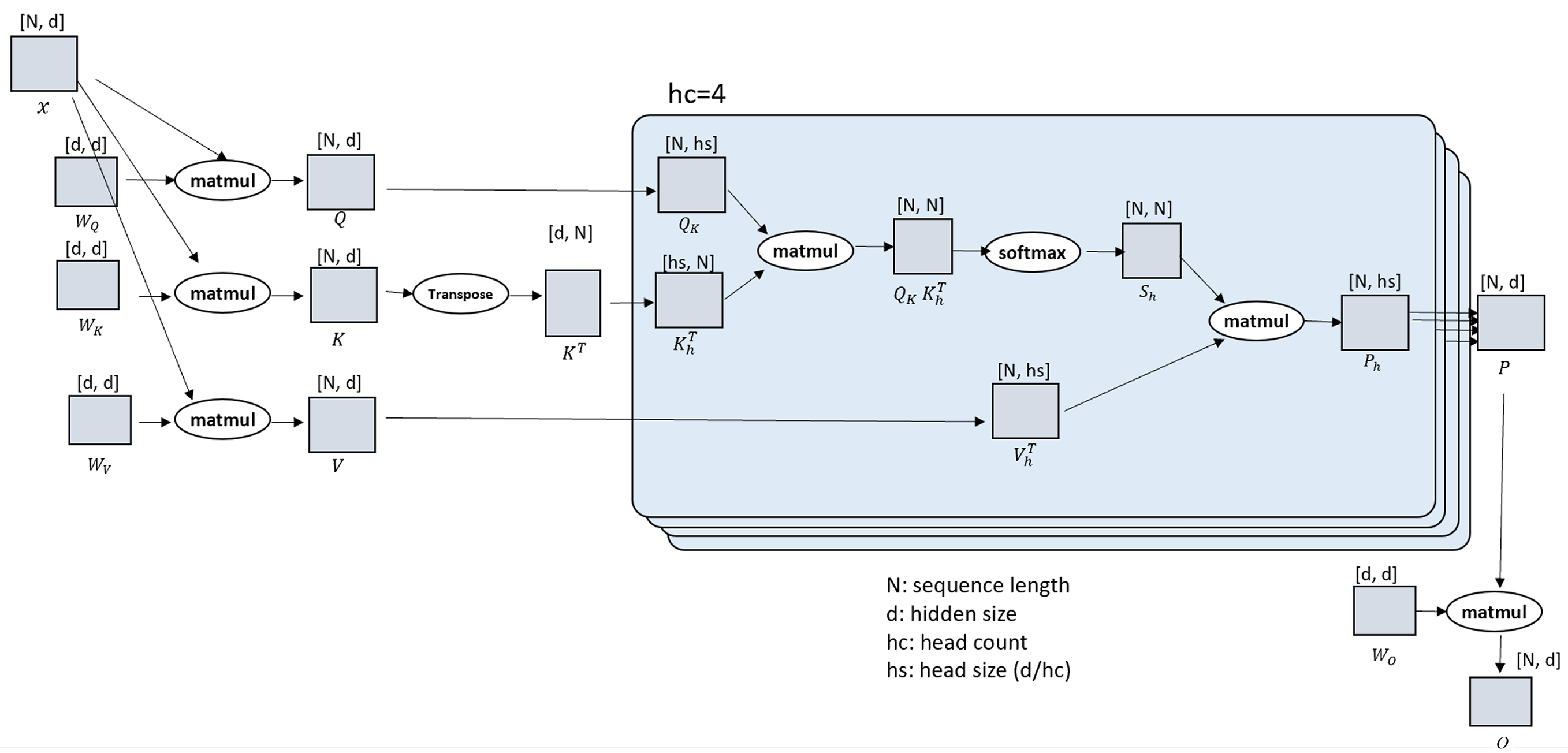
Image source: https://arxiv.org/abs/2309.14509
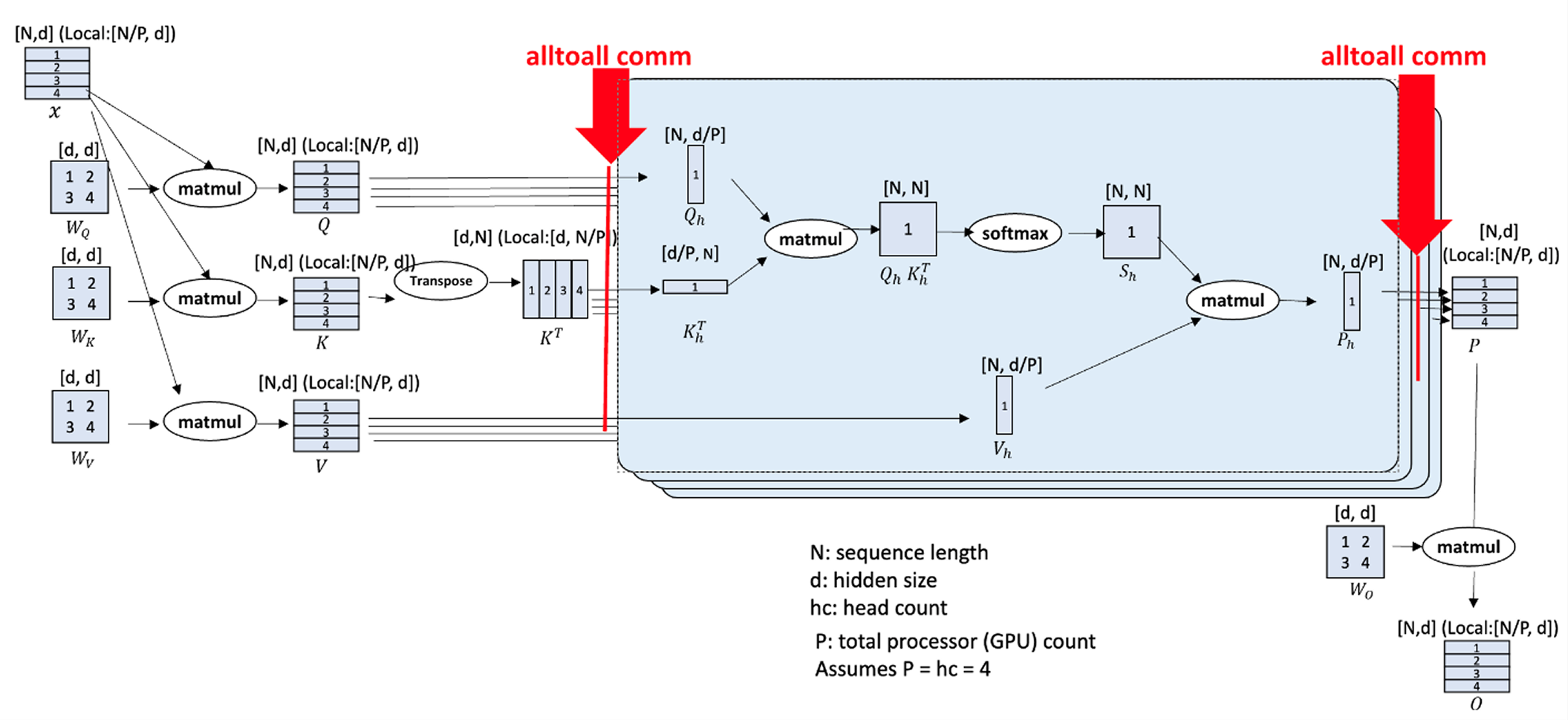
Image Source: https://arxiv.org/abs/2309.14509
Ring Attention component in Hybrid Parallelism
The second component is the Ring attention mechanism, which focuses on circulating key and value blocks among GPUs in a ring topology to compute full attention without duplicating large memory footprints.
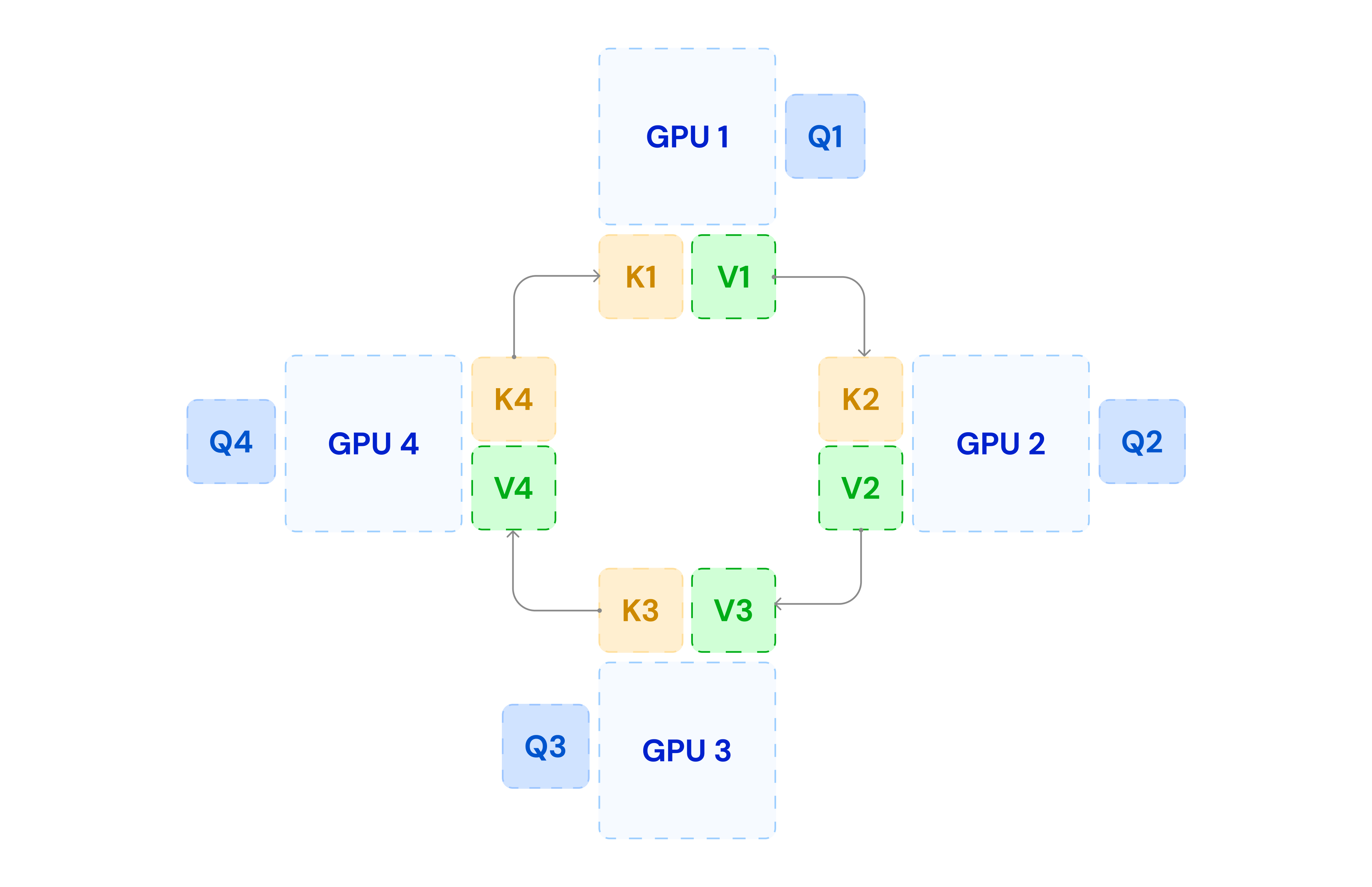
Core Mechanism
Each GPU begins with its local set of Q/K/V tensors and computes the local attention product:
Q_local · K_localᵀ
After this step, a communication phase begins:
- Each GPU sends its K_local and V_local tensors to the next GPU in the ring.
- Simultaneously, it receives a new K/V block from the previous GPU.
- Each GPU computes the next partial attention contribution using the newly received tensors.
- This process continues until every GPU has processed all K/V blocks from all peers.
Advantages
- Head-agnostic scalability: Performance is not limited by the number of attention heads.
- Hardware-flexible: Suitable for models or systems where head sharding is impractical or leads to load imbalance.
Limitations
- Communication intensity: Each iteration requires synchronized exchange of K/V blocks, which can incur significant latency, especially on interconnects with lower bandwidth.
- Bandwidth dependency: Throughput scales with the quality of the GPU interconnect (e.g., NVLink vs PCIe).
Why Hybrid Parallelism?
Neither approach is universally optimal:
- Ulysses: great memory scaling, but less effective when H is small or interconnect is modest.
- Ring: head-agnostic scaling, but higher comms per step.
Hybrid Parallelism mixes both to exploit their strengths and remove their weaknesses:
- Use Ulysses where sequence sharding yields the biggest wins.
- Use Ring where head sharding is awkward or where we want head-agnostic scaling.
- Achieve higher parallel degrees, lower comms than pure Ring, and better balance than pure Ulysses.
Hybrid Parallelism: device-mesh view
We organize GPUs into a 2-D mesh and shard along two orthogonal dimensions:
- Ulysses dimension: shards sequence N.
- Ring dimension: circulates K/V within each ring group.
Example: 8 GPUs as a 2×4 mesh
- Ulysses axis: 2 GPUs
- Ring axis: 4 GPUs
1. Split sequence first along Ulysses:
N_U = N / 2
2. Within each Ulysses shard, split work across a ring of 4 GPUs:
- Each GPU in a ring handles a quarter of that shard’s work via Ring attention passes.
Per-GPU tensor view (conceptual):
[B, H, N / (2×4), D]
(H may or may not be explicitly split; hybrid keeps head layout flexible while the ring focuses on K/V movement.)
Resulting properties with Hybrid Parallelism
- Memory savings of Ulysses: sequence sharding controls K/V cache size.
- Head-agnostic scalability of Ring: works well even when H is small.
- Higher parallelism degrees: 2-D mesh composes shardings cleanly.
- Lower comms than pure Ring: Ulysses reduces the total K/V footprint each ring must circulate.
- Better balance than pure Ulysses: Ring dimension provides extra parallel slack and smoother scheduling.
How it runs at a high level
- Partition the sequence across the Ulysses dimension (each group sees N_U).
- Within each Ulysses group, perform Ring attention passes across its ring of GPUs.
- Accumulate partial attention scores locally at each step.
- Combine contributions to produce the final per-token outputs for each shard.
- Concatenate shards across the Ulysses dimension to recover the full sequence output.
This design maintains standard attention math while restructuring the who-owns-what mapping to fit large N with practical interconnect costs.
Conclusion
Hybrid Parallelism unlocks long-sequence Video DiT inference on multi-GPU systems. By sharding N where it matters and circulating K/V where it’s efficient, you get the memory savings of sequence parallelism, the head-agnostic scaling of Ring, and lower end-to-end latency than either method alone.
If you’re pushing 720p+ video generation with tens of thousands of tokens per clip, Hybrid Parallelism is the most practical path to fit, speed, and scalability without compromising attention correctness.
Contact Us to know more about our optimizations and how it can fit your use case.



