

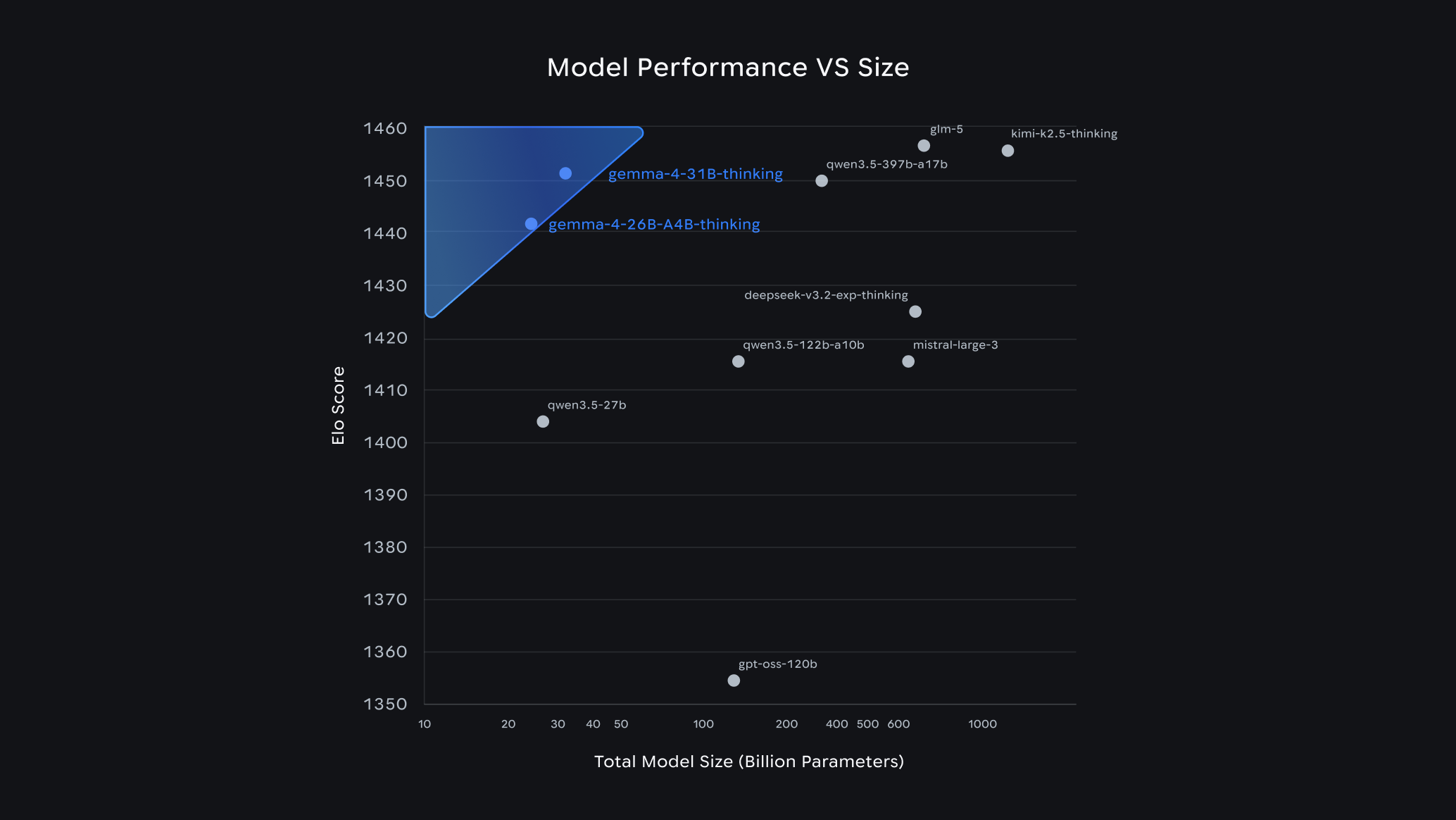
The open-weight vs. closed-source gap is closing and Gemma 4 is one of the clearest data points yet. Google DeepMind's latest release isn't an incremental update. It's a full architectural rethink: hybrid attention for 256K context, a 550M-parameter variable-resolution vision encoder, interleaved multimodal inputs, and benchmark numbers that compete with Kimi K2.5, Qwen 3.5 397B, and GLM5 models that are 10–30× larger by parameter count.
Simplismart now serves Gemma 4 26B MoE at 88.14 tokens/sec and 31B Dense model runs at 149.44 tokens/sec on optimized shared endpoints available today, OpenAI-compatible API, no infrastructure overhead. Here's what actually changed, and why it matters for your Gemma 4 deployment.
Why Gemma 4 Is an Architectural Departure, Not an Incremental Release
Most model updates optimize within an existing architecture. Gemma 4 makes structural changes that affect inference behavior, memory consumption, and what the model can actually do and they have direct implications for how you plan your Gemma 4 deployment.
In a nutshell, every previous Gemma model forced a tradeoff between context length, quality, and multimodal capability. Gemma 4 doesn't!
The full model family spans Dense and Mixture-of-Experts (MoE) architectures:
The "E" models use Per-Layer Embeddings to squeeze more capability out of fewer active parameters, built for on-device deployment. The 26B MoE activates only 3.8B parameters per inference pass, making it the cost-efficient workhorse. The 31B Dense is the production-grade option: full parameter count, 256K context, full multimodal support, no architectural compromises.
Apache 2.0 license across all variants. No usage restrictions, no permission requirements for commercial deployment.
The Architecture Decisions That Matter
Hybrid Sliding-Window + Global Attention
Running 256K context naively means the KV cache grows linearly with sequence length. At 256K tokens, that's a memory budget that makes most attention implementations impractical.
Gemma 4 solves this with interleaved local and global attention. Local layers apply sliding-window attention over nearby context: efficient, bounded memory. Global layers reason across the full sequence, but only where necessary. The final layer always uses global attention to ensure long-range coherence.
To keep memory sane at full context depth, global layers use unified Keys and Values with Proportional RoPE (p-RoPE), a position encoding variant that scales relative position biases proportionally with sequence length, preventing degradation at the edges of the context window.
The practical result: you can feed a 256K-token input without blowing your GPU memory budget. This is engineering, not marketing.
Variable-Resolution Vision Encoder
The 31B model ships with a ~550M parameter vision encoder, nearly 4× larger than the ~150M encoders in the E-series models. More importantly, it processes images at their native aspect ratios and resolutions, without resizing or padding to a fixed square.
This matters more than it sounds. Documents are tall and narrow. Panoramic photos are wide. Charts and dashboards are landscape. Forcing every image into a fixed square loses spatial information before the model ever sees the content. Gemma 4 processes the native shape, which means fewer pre-processing steps in your pipeline and better performance on structured visual content like PDFs, slides, and screenshots.
Interleaved Multimodal Input
Most vision-language models expect a fixed structure: image first, then text. Gemma 4 accepts freely interleaved text and image inputs in any order within a single prompt: question, image, more context, another image, continuation.
For multi-step visual reasoning or document analysis where context and visuals are naturally interwoven, this removes the need to artificially restructure your input.
Shared KV Cache
In the final layers, Gemma 4 reuses K and V tensors from the last layer that computed them rather than projecting fresh ones per token. This applies separately to sliding-window and full-attention layers, each sharing within its own group.
The quality impact is negligible. The savings are real: lower memory pressure, fewer FLOP operations, and meaningful throughput improvement on long sequences. This is one reason the 31B can sustain 149.44 tokens/sec on Simplismart. The architecture is built to be inference-efficient, not just accurate.
Per-Layer Embeddings (E-series)
Standard transformers force a single embedding vector to carry all layer-specific information through the entire forward pass. Gemma 4's E-series models use Per-Layer Embeddings (PLE) to address this bottleneck.
PLE adds a parallel, low-dimensional pathway alongside the main residual stream. For each token, it generates a small conditioning vector per layer by combining a token-identity lookup and a learned projection of the main embeddings. Each decoder layer then uses its dedicated vector to modulate hidden states after attention and feed-forward operations.
The effect: each layer receives token-specific information exactly when it's relevant, rather than frontloading everything into the initial embedding. Because the PLE dimension is much smaller than the main hidden size, you get meaningful per-layer specialization without a proportional increase in parameter count.
Gemma 4 Benchmarks
The 31B instruction-tuned model produces results you'd expect from a much larger closed-source model:
* Kimi K2.5 reports AIME 2025 at 96.1%
Source: Google Deepmind
Gemma 4 31B is competitive with Kimi K2.5, a model with 30× more total parameters and roughly comparable active parameters. That's not an incremental improvement over Gemma 3; it's a capability step change. The AIME improvement from 20.8% to 89.2% and a 2,040-point jump on Codeforces ELO represent a genuine architectural dividend, not benchmark optimization.
What You Can Actually Do With Gemma 4
- Document and image analysis: The variable-resolution encoder handles PDFs, screenshots, charts, handwriting, and OCR across 140+ languages natively. No resizing, no pre-processing pipeline required.
- Video understanding (31B): The 31B model processes sequences of frames from video inputs. Audio support is not included in the 31B and 26B variants. If your workload requires speech recognition or speech-to-translated-text, the E2B and E4B models cover audio natively; the right choice for voice-adjacent or edge deployment use cases.
- Long-context pipelines: 256K tokens is large enough to process entire codebases, document sets, or extended conversation histories in a single pass. For RAG pipelines, this means you can reduce or eliminate chunking overhead by feeding more context directly.
- Multilingual workloads: Pre-trained on 140+ languages, with strong instruction-following across 35+ in the instruct-tuned variants. The 31B achieves 88.4% on MMMLU, evidence of genuine generalization, not just English-first training with multilingual fine-tuning applied afterward.
- Coding and reasoning: Codeforces ELO of 2150 puts the 31B in competitive programmer territory. For code review, generation, or complex reasoning pipelines, quality is not the bottleneck.
Gemma 4 Deployment on Simplismart: Production-Grade Throughput
Simplismart has applied production inference optimizations to both the 31B and 26B variants, resulting in throughput numbers that make Gemma 4 deployment viable for high-volume workloads on shared infrastructure:
These are production measurements on Simplismart infrastructure, not synthetic benchmarks. At 149.44 TPS, a 31B Dense model is viable for real-time applications, not just batch evaluation. At 88.14 TPS, the 26B MoE gives you a cost-efficient alternative for throughput-sensitive workloads where you don't need the full Dense parameter count.
The API is OpenAI-compatible. If you're already using the OpenAI SDK, the switch is a base_url change.
Quick Start
1. Log in to Simplismart and open the model marketplace
2. Search "Gemma 4 31B Instruct". The shared endpoint is accessible right now.

3. Copy the endpoint URL and add it under the base_url parameter and generate an API key from Settings → API Keys and add it under the api_key parameter.
4. Use the client below: text, image, and video, one endpoint.
from openai import OpenAI
client = OpenAI(
api_key="SIMPLISMART_API_KEY",
base_url="https://api.simplismart.live"
)
# --- Text ---
def ask(question):
res = client.chat.completions.create(
model="google/gemma-4-31B-it",
messages=[{"role": "user", "content": [{"type": "text", "text": question}]}]
)
return res.choices[0].message.content
# --- Image ---
def describe_image(image_url, question="What is shown in this image?"):
res = client.chat.completions.create(
model="google/gemma-4-31B-it",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": question},
{"type": "image_url", "image_url": {"url": image_url}}
]
}]
)
return res.choices[0].message.content
# --- Video ---
def describe_video(video_url):
res = client.chat.completions.create(
model="google/gemma-4-31B-it",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "Describe what is happening in this video."},
{"type": "video", "url": video_url}
]
}]
)
return res.choices[0].message.content
if __name__ == "__main__":
print("Text:", ask("What is 2+2?"))
print("Image:", describe_image(
"https://raw.githubusercontent.com/google-gemma/cookbook/refs/heads/main/Demos/sample-data/GoldenGate.png"
))
print("Video:", describe_video(
"https://huggingface.co/datasets/merve/vlm_test_images/resolve/main/concert.mp4"
))
Gemma 4 Deployment Options: Shared vs. Dedicated
The same inference stack powers both Gemma 4 deployment options. What changes is how you pay for capacity and what guarantees you get.
Shared is pay-per-token; no infrastructure provisioning, no reserved compute, no GPU fleet to think about. Dedicated locks in GPU resources exclusively for your workload, with SLA-backed latency and throughput floors.
Shared endpoint is right for:
- You want immediate access with zero provisioning
- Your workload traffic is variable or unpredictable and you'd rather pay for API usage than reserve capacity
- You're running multimodal pipelines, long-context RAG, or reasoning workloads where throughput is sufficient and you don't need guaranteed availability under burst load
Dedicated deployment is necessary when:
- You need throughput beyond shared infrastructure capacity for high-concurrency workloads
- You're shipping to production and require SLA-backed latency guarantees
- Data has compliance constraints like HIPAA, SOC 2, GDPR that require single-tenant isolation
- You want to deploy models on Your Own Cloud and need the model running within your own infrastructure with the ability to manage your own GPU fleet
Most teams start on shared, validate the model against their workload, then move to dedicated before going live. The API surface is identical; no code changes required.
For deployment configuration and optimization options, see the model optimization docs and deployment docs.
The Honest Assessment
Gemma 4 is the strongest open-weight multimodal model Google has shipped. The reasoning numbers aren't inflated by benchmark optimization. A 4× AIME improvement and a 2,000-point Codeforces ELO jump represent a genuine architectural step change, not fine-tuning on test-adjacent data. The 256K context window is large enough to be useful in real applications. The Apache 2.0 license removes the legal friction that makes proprietary models a liability for production systems.
The gap between open-weight and closed-source is closing faster than most teams expected. Gemma 4 deployment at 149.44 TPS on Simplismart is a concrete example of what that looks like in production: a 31B-class model, multimodal, 256K context, competitive with 1T-parameter alternatives, no GPU fleet to manage.
Start on the shared endpoint today or contact the team for a dedicated deployment tuned to your specific workload.



