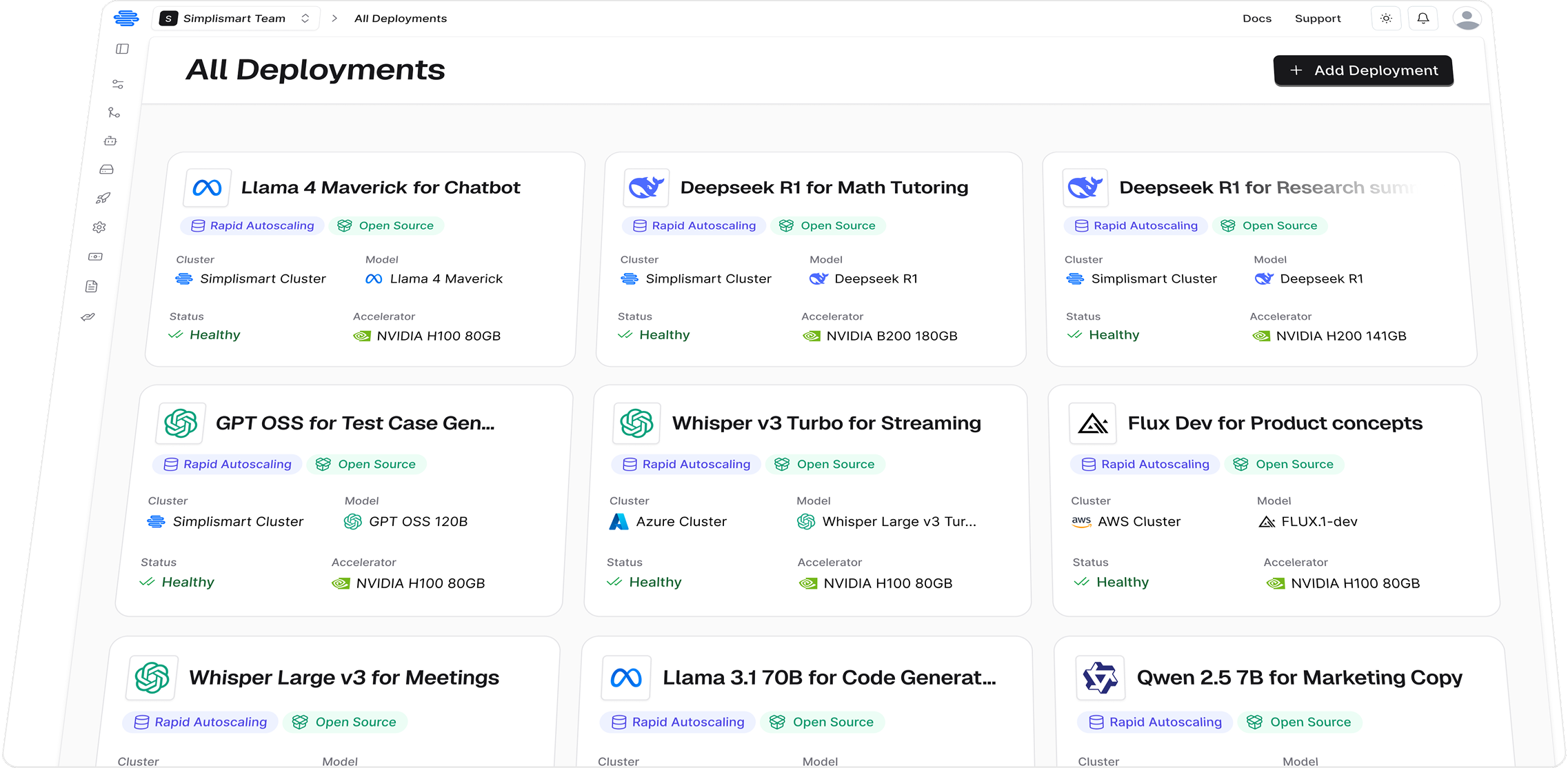
Deploy and scale
Inference that adapts to your needs













Tailor-made inference for any model at scale
Pick from 150+ open-source models or import custom weights

Get started quickly and pay-as-you-go
Import custom models from 10+ cloud repositories
Supports LLMs, VLMs, Diffusion and Speech models
Deploy in our cloud or yours
Deploy in any private VPC or on-prem setup
One control plane to manage deployments across clouds
Native integration with 15+ clouds
B200s, H100s, A100s, L40S, A10G available across the globe
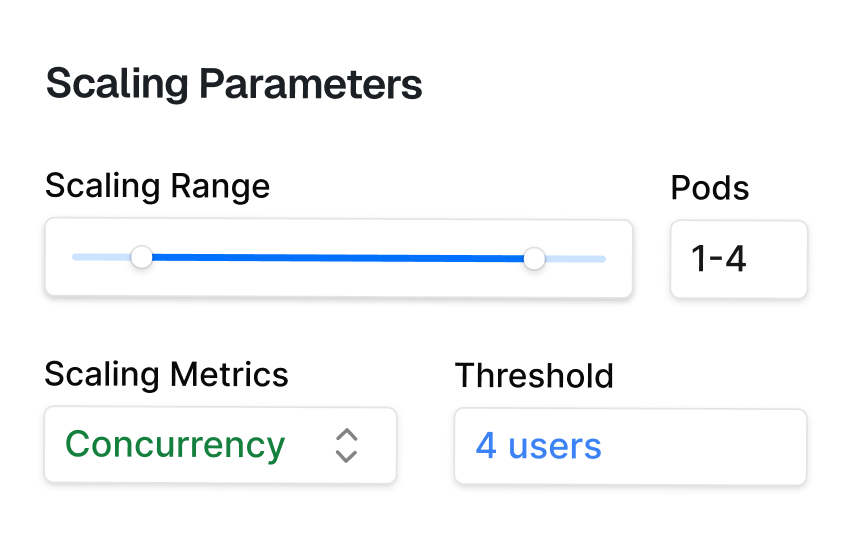
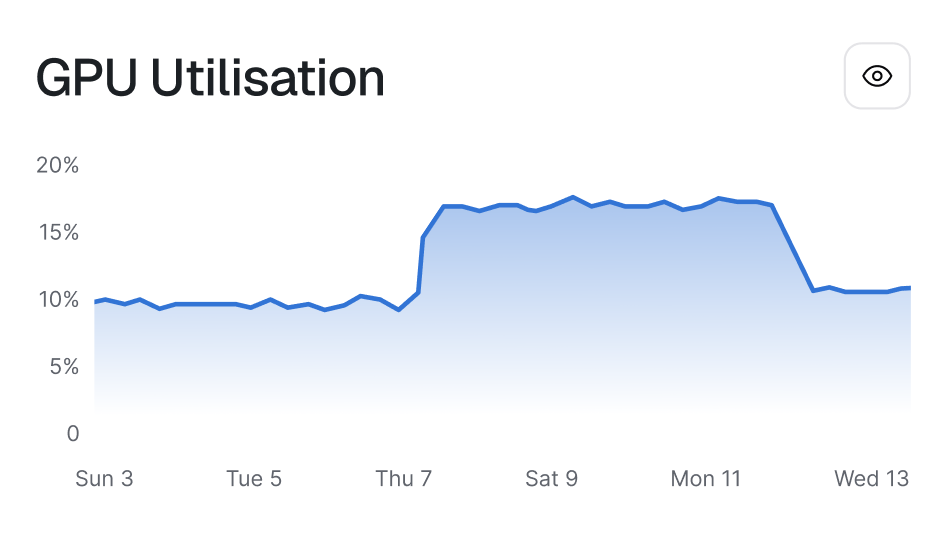
Scale up in less than 500ms
Rapid auto-scaling for spiky traffic
Scale based on specific metrics to serve strict SLAs
Scale-to-zero based on traffic
Built for performant runtime
Custom built CUDA kernels
Get lowest TTFT and E2E latency
or maximize throughput with most affordable costs

The most common
mistake in inference
One size does not fit all
Your product deserves tailor-made inference, not generic APIs
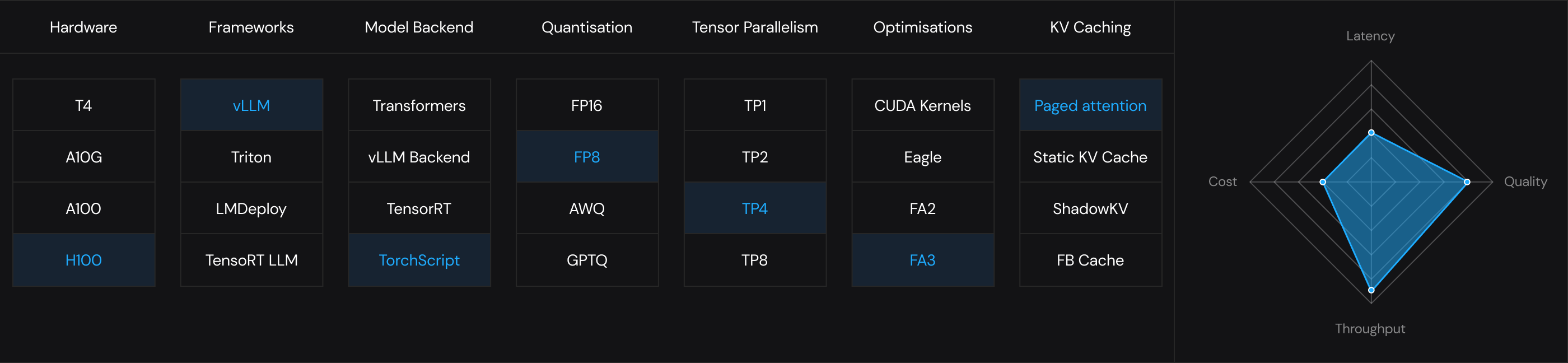
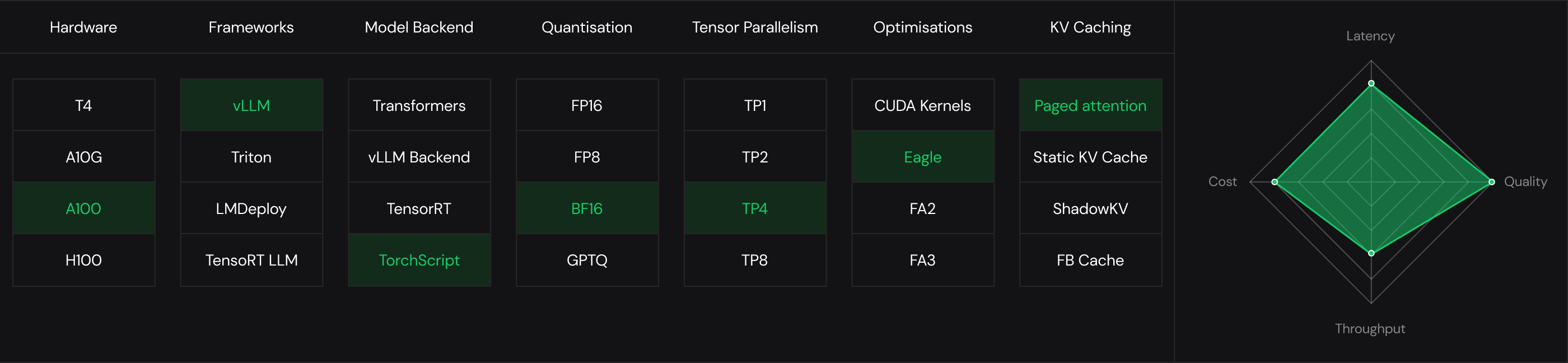
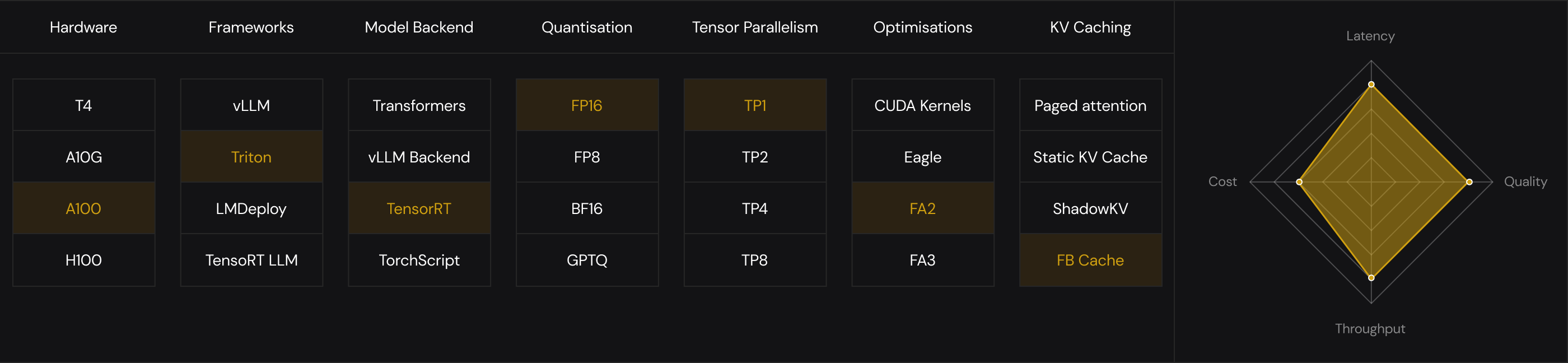

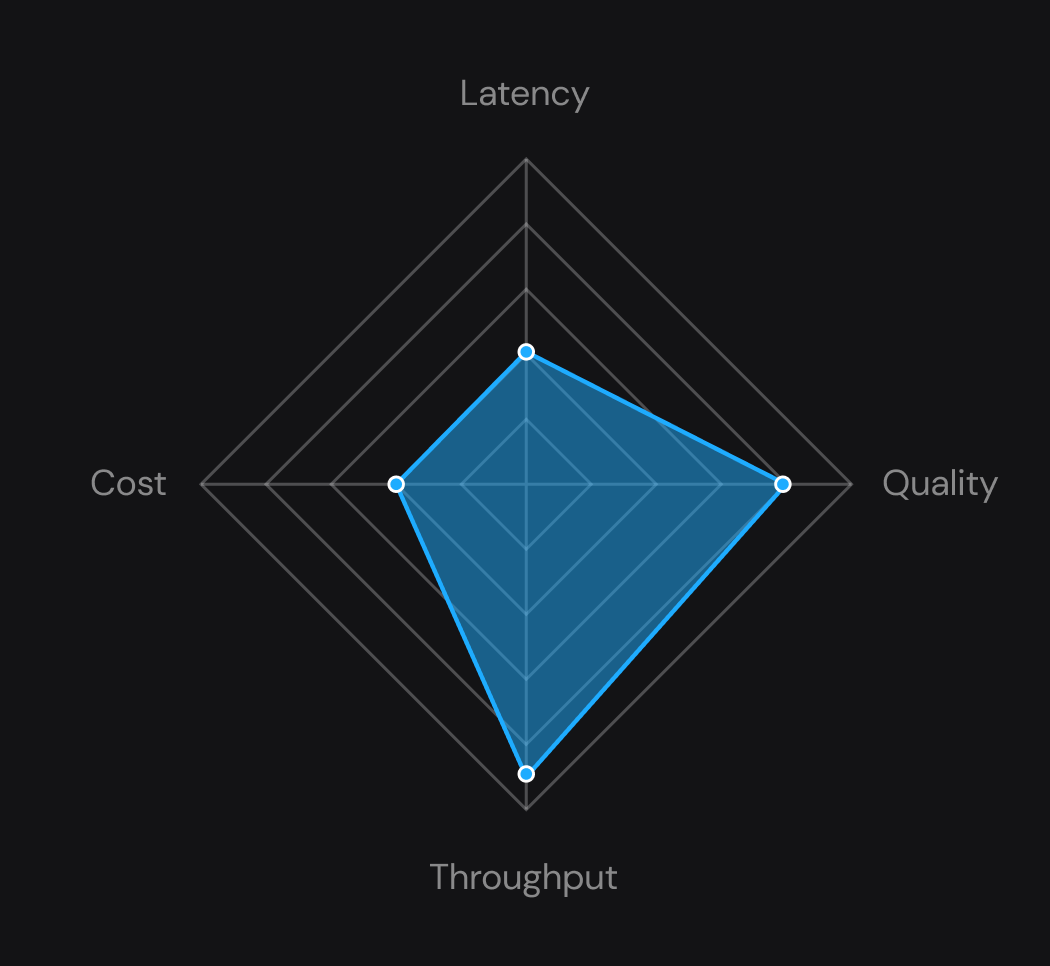

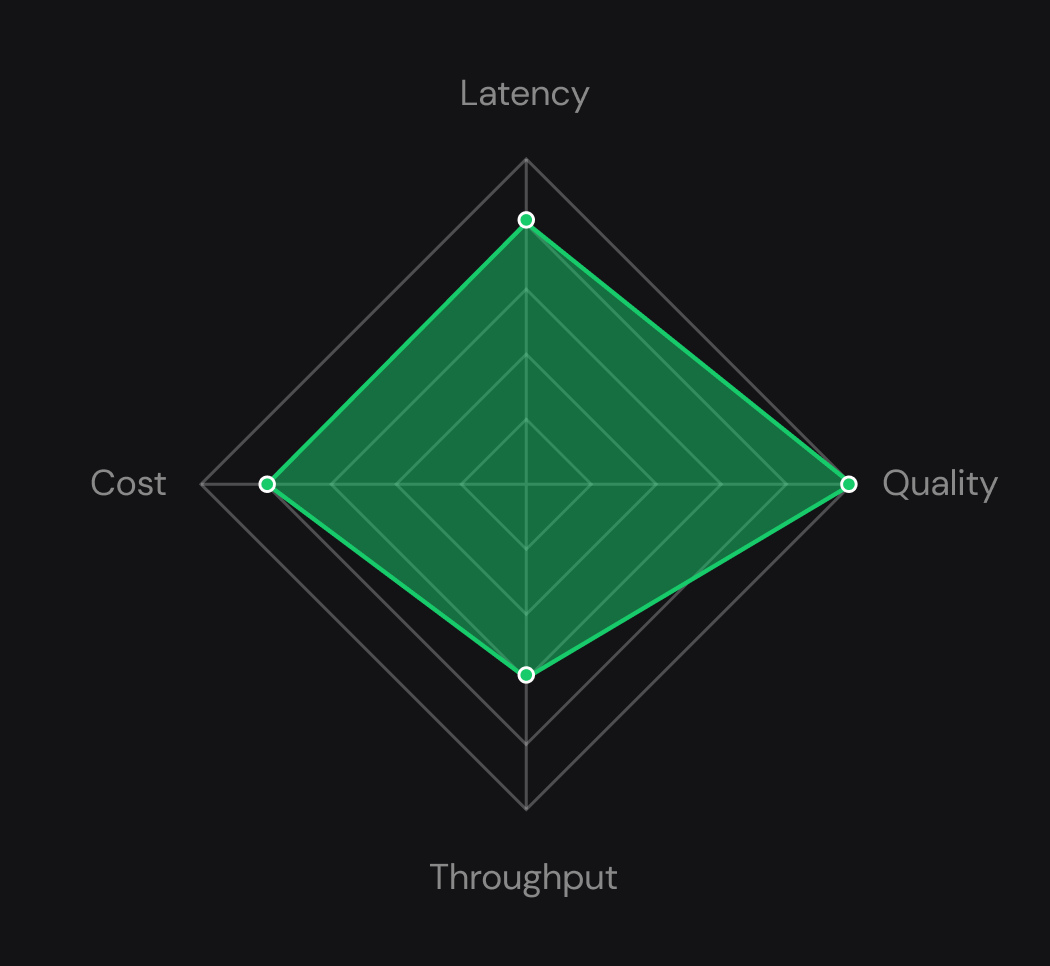

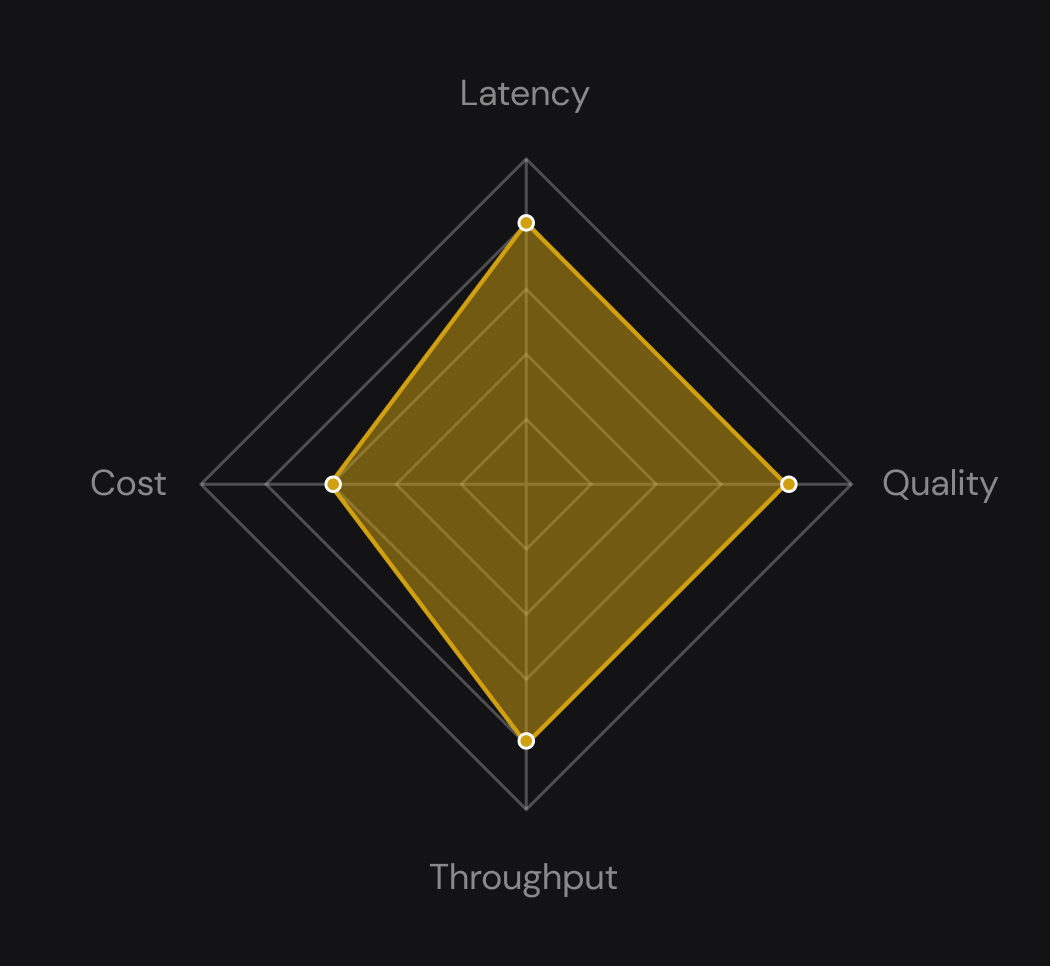
Tested at Scale. Built for Production
Reliable deployments with 99.99% uptime, enterprise-grade security, and completely compliant with highest standards








Hear from our Partners
Don't take just our word for it, hear from companies that Simplismart has partnered with





Your AI Stack, Fully in Your Control
See how Simplismart’s platform delivers performance, control, and modularity in real-world deployments.


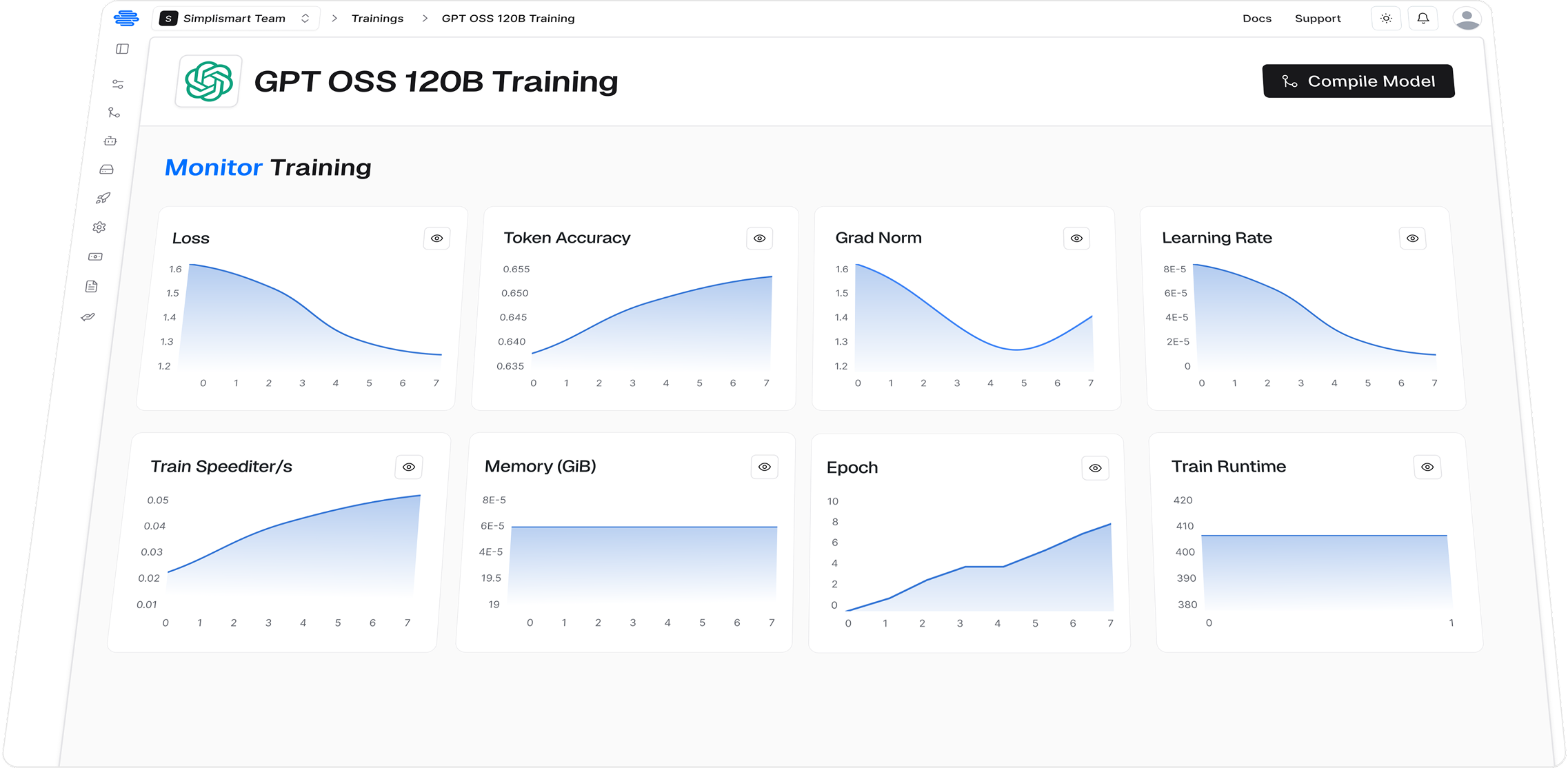






Built to Fit Seamlessly Into Your Stack
From GPUs to Clouds to Data Centers - Simplismart is engineered to integrate natively with your infrastructure and ecosystem partners.



