- We raised $7 million in our Series A funding round led by Accel
- Simplismart is the fastest inference engine for your generative AI workloads
- E2E MLOps platform with terraform-like orchestration
I remember crying out loud about a loop I was stuck in as an MLE: late nights, repetitive code, and the complexity of optimising the ML models in production. I was fresh off solving infrastructure problems at Oracle Cloud, and my friend (now co-founder) Devansh was refining search algorithms at Google Search. After countless hours of debugging production pipelines, we realised this process was broken. Skipping the more extended version that includes winning two hackathons and rejecting an acquisition offer, we soon realised we shared frustration towards the current state of MLOps. That’s when we decided to simplify ML production pipelines via Simplismart.
We started before generative AI was normalised, and the world has changed quite a bit since then. With the advent of LLMs and their parallels, AI has advanced enough to span several use cases. Many enterprises want to adopt AI but aren’t capable of realising value from their ML ambitions. Third-party APIs are readily available but are expensive, rigid, and pose data security concerns. Every company has different inference needs: One size does NOT fit all. APIs are not tailored to scale for bursty workloads and cannot tweak performance to suit needs. Businesses need to control their cost vs performance tradeoffs. This will be the primary reason for a shift towards open-source models, as companies prefer smaller niche models trained on relevant datasets over large generalist models to justify ROI.
No one wants to rent their AI, but owning it is not easy. Deploying extensive models in-house comes with its hurdles: scaling infrastructure, CI/CD pipelines, access to compute, model optimisation, and cost efficiency, all requiring highly skilled machine learning engineers. Currently, there are two different off-the-shelf solutions in the market with their striking limitations:
Let me re-iterate: With the growing quantum of workloads and model size, one size does not fit all. We are developers at heart and understand a developer’s need to presume control over their systems - hence, we wanted to build exactly what we wish we had. As a result, we’ve spent the last 2.5 years building Simplismart to become the most robust infrastructure for stability and the fastest inference of your generative AI workloads. We have created a terraform-like declarative language that helps users fine-tune, deploy, and observe generative models in production. This language simplifies every step of the workflow, spanning deployment and production.
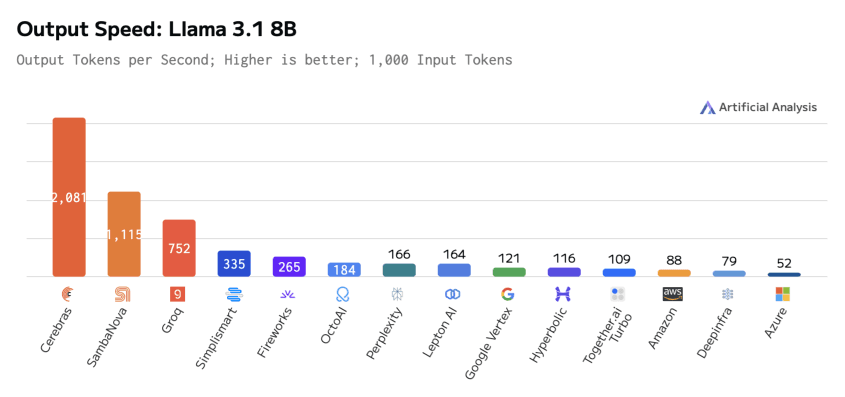

What makes us the fastest inference engine in the world? Three layers of optimisation: model-serving layer, infrastructure layer, and model-GPU-chip interaction layer. These and known model compilation techniques help us deliver performant serving for ANY model. Our rapid autoscaling (fastest in the industry) & cold-start solutions help them control costs in the face of adverse bursty workloads. Our native workflows automatically serve large models in production, so users don’t need to worry about version management, roll-out, and observability. With Simplismart, 30+ enterprises scale their load as per requirement of times over without a minute of downtime (robust infra). Developers leverage Simplismart to deliver the best-in-class performance by personalising their inference engine without spending time on production pipelines and optimisation.
This is not a winner-take-all game. MLOps needs efficiency, and we couldn’t be geekier about it. Every team member building our platform has either of the three jobs: make the infrastructure stable workflows easy OR unlock new realms of model performance. This boosts the adoption of open-source models and redistributes the power, which is better for AI and society. We are building an emerging category of tools needed to support this adoption, much like we had tools to help us transition to cloud (Terraform), mobile (Android Studio), and data (Databricks, Snowflake).
One last thing, the money! We’re excited to announce that we’ve raised $7 million in a Series A round led by Accel. You can read more about it here, tldr: we’ve brought in some great folks to help us make Simplismart the founding stone of AI adoption for ages to come. We plan to spend this tranche on R&D and growth initiatives. The round also saw participation from our existing investors and some marquee angels we wanted on our side while building the company of our dreams. The capital will help us move faster to make the thing we have always wanted as engineers and always understood its need.
We are always looking for smart and fun people to join our team. If you are an engineer looking to build with Simplismart’s platform, check out our playground and docs. If you like what you see, feel free to contact us at contact@simplismart.ai, or record your interest here and let us reach out to you. See you around!
- by Amritanshu Jain, CEO and Co-founder, Simplismart
See the difference. Feel the savings. Kick off with Simplismart and get $5 credits free on sign-up. Choose your perfect plan or just pay-as-you-go.
.svg)

